
Olaf Pohlmann
Read all my blogsIn this short blog I want to point out a useful function when you have to transfer huge amounts of data between SAP systems. The function is /SAPDS/RFC_STREAM_READ_TABLE and it’s part of a broader software suite called SAP Data Services. What makes this function great is that it comes with just the right amount of options to tweak data transfer with respect to parallel processing, batch size and controllability in general. I will address each aspect in more detail.
By the way, previously SAP Data Services used another namespace and the function was named /BODS/RFC_STREAM_READ_TABLE.
General setup
First an overview of the parameters of this (remote-enabled) function:
| Name | Type | Description |
|---|---|---|
| QUERY_TABLE | Importing | Name of the table to retrieve data from |
| CALLBACK_FM | Importing | Name of the callback function |
| DELIMITER | Importing | Possible delimiter to use in the record set |
| BATCH_SIZE | Importing | Number of records of the intermediate record set |
| NUMB_OF_LINES | Importing | Number of records to retrieve in total |
| PROJECTIONS | Table | Set of columns to retrieve |
| SELECTIONS | Table | Selection criteria (where clause) |
Parallel processing
Especially when transferring large amounts of data, you want to speed up processing time as much as possible. One way to achieve this is by using parallel processing. The function supports this by means of providing selection criteria in de SELECTIONS-parameter. This is just a dynamic where clause. So you start the first call with selection criteria for the first subset, the second call with criteria for the second subset and so on. I will show an example of how this can be easily implemented.
Runtime
Because RFC-calls, like dialog processes, have a maximum runtime, the system might cancel long running calls. Again, the SELECTIONS-parameter is the most important parameter.
Callback function
All pretty common so far and if you’re familiar with function RFC_READ_TABLE, this one can do the same. But function /SAPDS/RFC_STREAM_READ_TABLE has one additional option which makes a world of difference and that is the ability to provide a callback function. The remotely selected data is passed back to this function in the calling system for further processing. It must have the following parameters:
| Name | Type | Description |
|---|---|---|
| EOP | Exporting | Indicator which the calling system can set to stop the current transfer |
| E_TABLE | Table | The actual records (in a generic flat format) |
| READ_ERROR | Exception | Exception to indicator errors |
With this callback mechanism you handover some control to the system which holds the data. This enables the next great feature, batch size.
Batch size
Processing huge amounts of data can be challenging. You easily run into memory overloads or experience extremely long runtimes while processing and/or storing this data. The possibility to specify a batch size sets a limit on the number of records that is being processed at a specific time.
Another way to influence the batch size is the PROJECTIONS-parameter. Here you specify the set of columns to retrieve and thereby reducing the batch size.
Example
For a migration project I worked on, we had a special intermediate system in which we collected all relevant data from various systems. This so-called staging system was then used to do all sorts of migration activities. One of the source systems contained a table with billions of records. The approach was to use job scheduling so the data transfer could run unattended but could still be easily monitored.
First we developed a simple program to act as a wrapper around function /SAPDS/RFC_STREAM_READ_TABLE. Then we scheduled 10 jobs with this program as the only step but in each job with a different selection. A batch size of 50.000 records turned out to be the optimal size for most tables. Below an illustration:
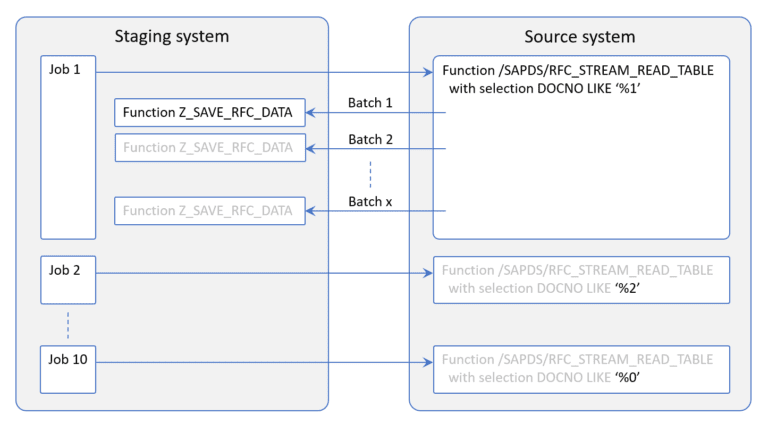
In this particular case we used the last (!) digit of a document number as the main selection criterium. In this way you split all data into 10 subsets of similar size. On a relational database you normally don’t execute such a, poor performing, query but this HANA-powered system handled it effortless.
We had more complex scenarios but I hope you get the general idea.

Receive our weekly blog by email?
Subscribe here:

